随着业务的不断增多,为满足不同场景下对计算时延和吞吐的需求,各式各样的数据源大显身手。然而,由于不同数据源的发展历程不同,迭代速度不一,无法向用户提供统一的数据处理范式。且数据源所处介质天然隔离,交叉关联分析阻碍重重,导致数据人员要为此承担高额的学习和分析成本。
那么面对这些问题,360是如何构建高效统一的SQL查询引擎呢?以下内容来自ArchSummit全球架构师峰会 奇虎360大数据中心资深研发工程师 刘思源的演讲内容整理,以飨读者。
日益复杂的场景使得业务加工数据效率低下
360内部有很多业务线,除了大家平时熟知的PC安全卫士、360浏览器、360搜索以及移动端的手机卫士等应用软件之外,还有很多其他领域的业务产品。下图为整个公司从资产角度呈现出的业务线概况。
Image may be NSFW.
Clik here to view.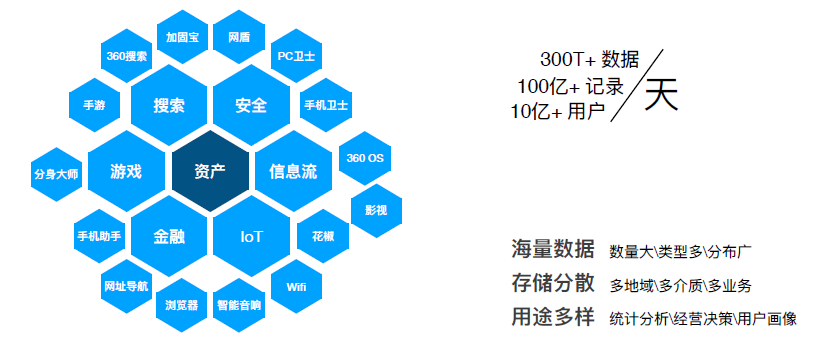
从图中可以看到,公司内业务方向主要分为搜索、安全、视频信息流、游戏、金融和 IoT 六个领域,以这些领域为核心由向外衍生出诸多产品,这些产品每日新增打点数据300T+,换算后有接近100亿+条记录,覆盖用户数达到10亿+。由于业务对数据的使用场景在时延和量级上有不同的需求,所以数据往往分散存储在诸多存储介质上,在进行数据产出时需要抽取合并不同介质的数据,以公司内部场景为例。