互联网的高速发展使得对数据实效性的要求越来越高,基于数据流的流计算越来越重要。以Flink为代表的新一代流计算引擎以其高吞吐、低延迟、checkpoint、state、time、window等特性方便了我们对数据流的高效处理。
Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算。Flink起源于德国柏林工业大学的一个研究项目Stratosphere,Flink从Stratosphere的分布式执行引擎开始,并于2014年3月成为Apache Incubator项目。2014年12月,Flink成为Apache顶级项目。
Why flink
high throughput & low latency。流计算任务对吞吐和延迟有着很高要求,Spark Streaming通过微批去实现流处理,而Flink是纯流式计算的思路,可以满足高吞吐和低延迟。
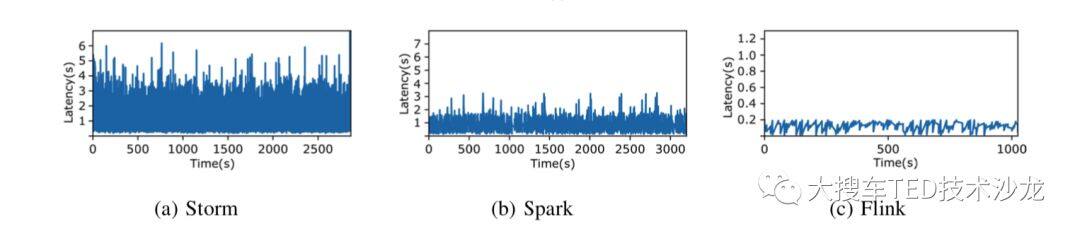
图1 latency对比
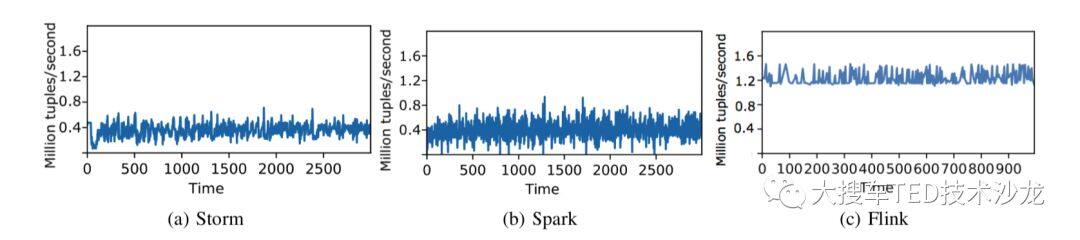
图2 throughput对比