本篇介绍深度学习在自然语言处理(NLP)中的应用,从词向量开始,到最新最强大的BERT等预训练模型,梗概性的介绍了深度学习近20年在NLP中的一些重大的进展。
在深度学习之前,用于解决NLP问题的机器学习方法一般都基于浅层模型(如SVM和logistic 回归),这些模型都在非常高维和稀疏的特征(one-hot encoding)上进行训练和学习,出现了维度爆炸等问题难以解决。并且基于传统机器学习的NLP系统严重依赖手动制作的特征,它们极其耗时,且通常并不完备。
而近年来,基于稠密向量表征的神经网络在多种NLP任务上得到了不错结果。这一趋势取决了词嵌入和深度学习方法的成功;并且深度学习使多级自动特征表征学习成为可能。因此,本文从词的分布式表征开始介绍深度学习在NLP中的应用。
分布式词表征(词向量)的实现
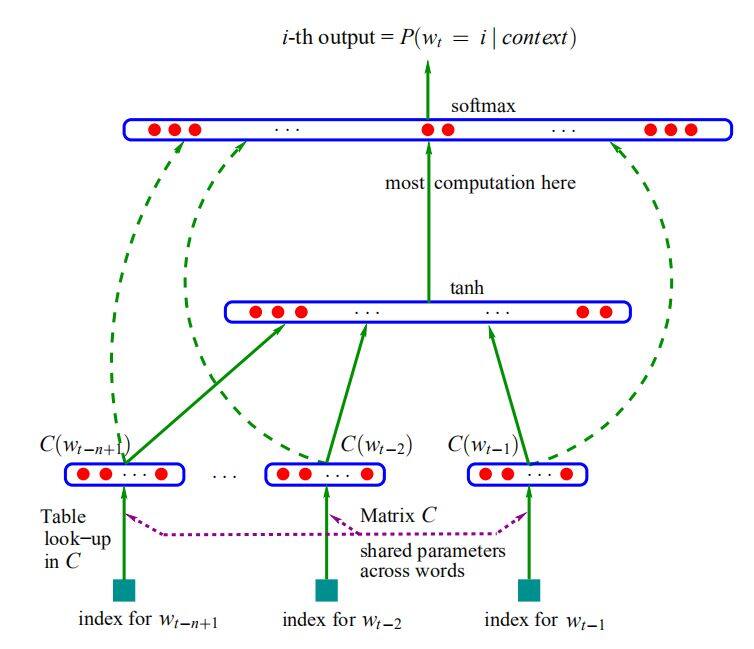
通常来讲,在2003年的《A Neural Probabilistic Language Model》中Bengio等人提出了神经语言模型(NNLM),而它的副产品,词向量,可以实现词的分布式表征。该文通常被认为是深度学习在自然语言处理中应用的开始。提出伊始,由于届时计算机计算能力的限制,该网络并不能较好的得到训练。因此,这一篇成果,在当时并没有得到相当的关注。其神经网络结构如下: